[Note: This post follows on from one on Neural Networks. If you’re new to Neural Networks, like me, this will make a lot more sense if you look at that one first! Neural Networks]
Deep Learning takes artificial intelligence to the next level.
It is both the most exciting and the potentially most scary part of AI.
It’s most often described with the following diagram, it’s a subset of machine learning, which itself is a subset of AI.
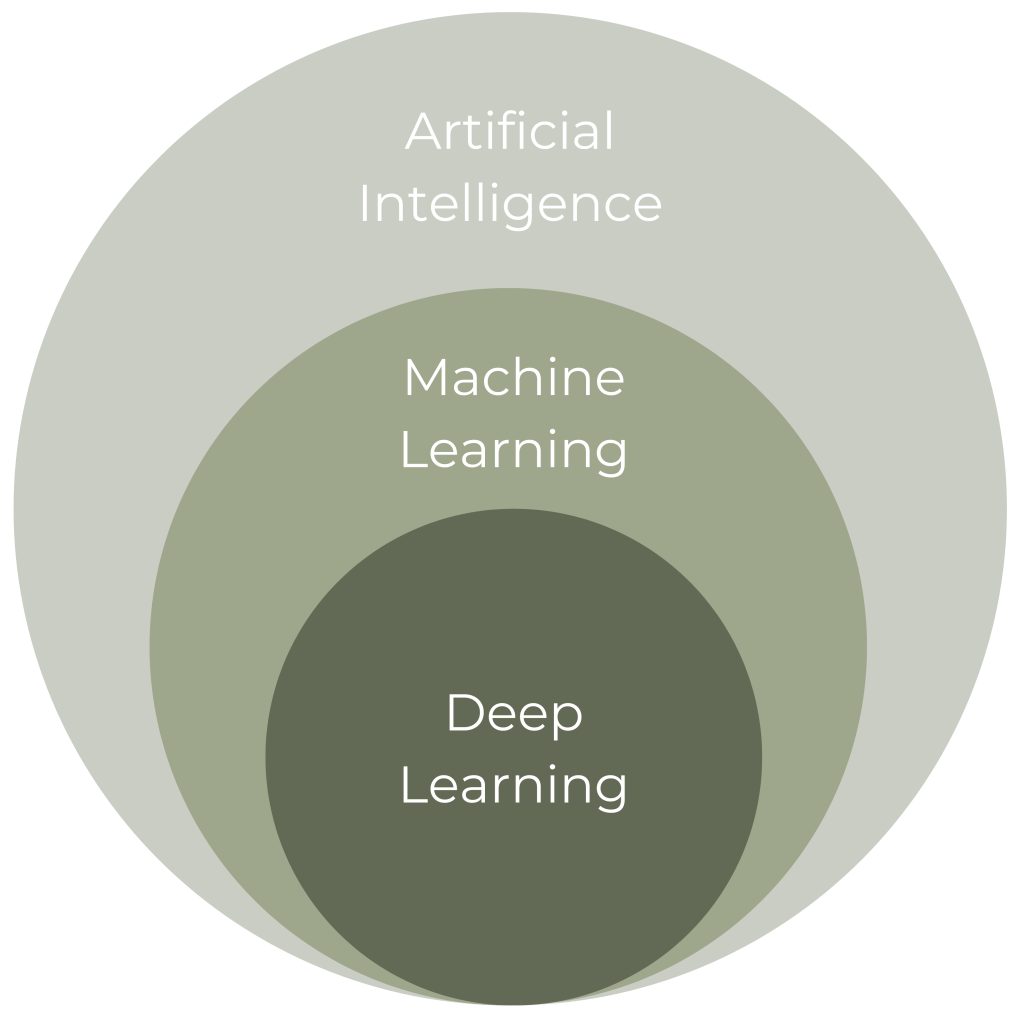
Artificial Neural Networks
In the previous example of an Artificial Neural Network, we imagined that a computer programmer teaches a computer how to answer a few different questions in order to make a decision.
This is how the majority of artificial intelligence works at the moment. A human will provide a machine with labeled structured data and tell it what to do with new data, creating a neuron.
They connect these artificial neurons together to recreate nuanced human intelligence.
Deep Learning
With Deep Learning, a few extra layers of artificial neurons are added.
These extra layers enable the computers to process data and extract information, without being told what to do.
As the excellent “State of AI Report” from MMC states:
Q// Deep learning is valuable because it transfers an additional burden – the process of feature extraction – from the programmer to their program//
(SOFAI, 2019, link)
This diagram from the same report visually represents the difference between Machine Learning and Deep Learning.
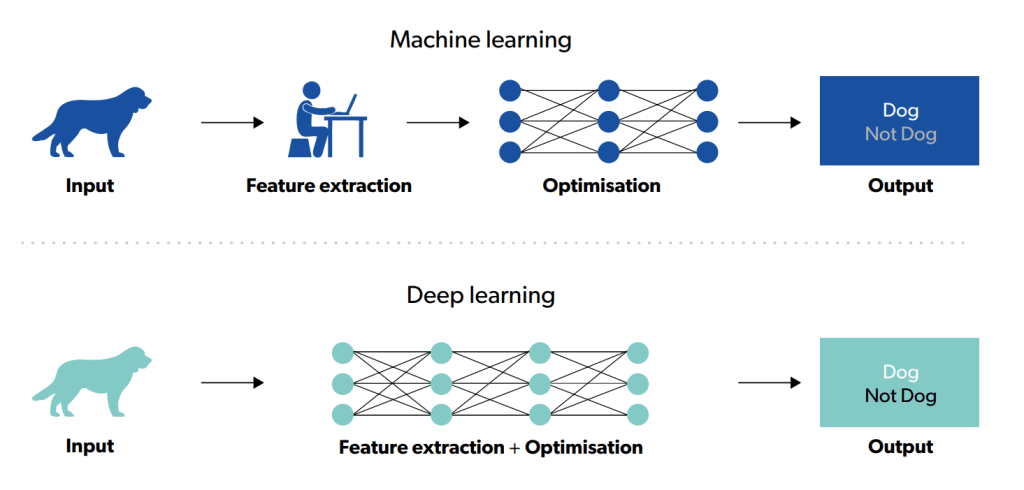
Example: Speech Recognition
Let’s take the example of speech recognition.
Can you imagine how complex it is for a human to teach a computer a language?
Firstly you have to teach all the vocabularly and grammatical structures. After that you have to teach the infinite variability in accents, tone, timing, and phrasing.
Histoical Speech Recognition
Historically, computers have been taught speech recognition by breaking down each word into component parts that humans can recognise
For example “Cat” would be split into three sounds which could be imagined as “K”, “Aa” and “Teu”. But in reality we know that sounds are a wave and even a short word like Cat can’t be split into three defined sections.
This is why most computer generated speak sounds very disjointed (think Stephen Hawking). We’ve only been able to teach computers language in chunks, so it’s been replicated in chunks.
But this is changing…
Words As Waves
As artificial neural networks are improved they can start to recognise the tiniest nuances in language and improve their speech recognition.
This is possible because they are training on gigantic sets of data.
Feeding the AI Machines
In 2019 Amazon had sold 100 million Alexa devices.
I reckon this number could be twice as many today. Each of those millions of devices is collecting data every single day.
That data is being fed back into artifical neural networks that are improving their speech recognition capabilities.
On top of Alexa, there is Google Assistant and Siri in every single iPhone.
Together these are creating billions of daily data sets that can help train and improve speech recognition with comparatively little human intervention.
Is Deep Learning a Good Thing?
There are many ethical considerations with AI.
In the context of Deep Learning the main benefit is the main concern: the Artificial Neural Networks can teach themselves.
There is a risk, therefore, that computers will make decisions beyond any human understanding. The current justification is that Deep Learning is the only way we can evolve AI to beyond human level intelligence. Therefore it’s essential to make AI truly useful and solve the world’s biggest problems.
My view is that arguing if it’s “good” or “bad” is futile. Deep Learning is here, computers are improving every day. If any one person or country stopped developing it, others would appear in its place. Ultimately, it’s down to us humans to show the computers ethical behaviours so that’s what they learn and replicate.

1 Comment