Q// Machine learning is a branch of artificial intelligence (AI) and computer science which focuses on the use of data and algorithms to imitate the way that humans learn, gradually improving its accuracy //
IBM 2020 (link)
In other words, Machine Learning aims to uncover what learning is and how we can get machines to do it. We could deploy machines to solve more tasks if we can get them learning better.
Importantly it’s often separated into two distinct camps:
- Supervised Learning
- Unsupervised Learning
The Game-Changer for Real Estate?
My hypothesis is that Unsupervised Learning is the game-changer for Real Estate. Supervised Learning always needs a human to tell it what to do, whereas Unsupervised Learning can work things out for itself.
Infinite Scenarios
As each building is unique there are infinite scenarios relating to that building. Physically things could go wrong in any element of the heating, electricals, plumbing, sewage, roof, cladding (scream), windows, foundations. Financially, there could be nuances in how & when the rent is paid, rent frees & rent reviews calculated or lease renewals agreed and then mortgage or loan agreements. And that’s before considering the multitude of legal restrictions, clauses in leases or rights of ways over land.
With so many variables, it’s impossible for a human to program a computer with all the possible scenarios. Assumptions are made and Rules of Thumb used. It’s the key reason why valuation in real estate is considered “An Art not a Science”.
Once computers have enough real estate data to teach themselves, they should be able to model scenarios more quickly and accurately than any human today.
I started to understand the power of Machine Learning through this simple sentence by Mo Gawdat:
Q// Think about it: when you or I have an accident driving a car, you or I learn, but when a self-driving car makes a mistake, all self-driving cars learn//
Gawdat, 2021, Scary Smart
Current Real Estate Learning Process
The current feedback loop in real estate is snail-like.
It could take a year to design a building and get planning, two years to build it and a year to lease it. That’s before it’s been in operation long enough to find snags or flaws. If the people involved in the start are still the ones involved 4 years later (and often they’ve moved on by then), they’re generally the only ones to learn.
Once computers start absorbing and learning all the data about real estate it can be shared with all other computers instantly. Therefore, when we consult with a computer to help make a decision in the future they’ll be better informed than any single real estate professional today.
Back to Supervised and Unsupervised Learning
Supervised Learning
This is when humans teach machines to do a specific task using labelled data.
A typical example is a spam filter. The program is taught IF you find these words or phrases, THEN send the email to junk. Nowadays they are generally pretty accurate. However, there are still occasions where they send emails to junk in error. I often find any email with “Finances” and related words, go to spam. That’s incredibly unhelpful when financial matters are time critical!
When you click on the “Not Junk” button on an email that’s been sent to junk, you’re effectively teaching the computer that the particular combination of words and phrases in that email are “Not Junk”.
Similarly, did you know that anytime you fill in one of those “I’m Not A Robot” pop-ups, you’re helping computers learn what a bus or traffic light or car looks like. This creates valuable human-verified data which is sold to the self-driving car manufacturers.
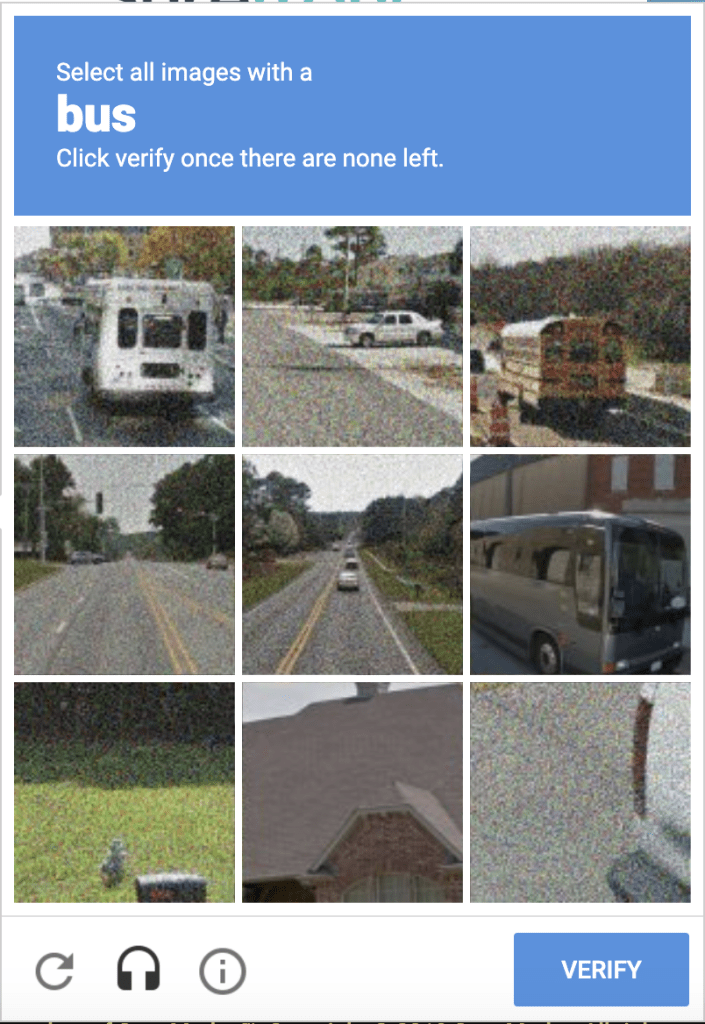
This shows various problems, firstly that Supervised Learning machines can only get better with improved input from humans. This (ironically) requires huge amounts of human resource and there will inevitably be errors due to human error in input.
It’s also reliant on the number of scenarios a human can input which is restricted by time and imagination.
Unsupervised Learning
With Unsupervised Learning programmers teach computers to search for patterns and draw conclusions without being programmed to directly find those conclusions.
For example, rather than telling the computer which words make emails “Junk” or “Not Junk” the computer could find patterns such as “these types of email were deleted before a human had time to read it” and therefore might be spam.
In theory, this should lead to unbiased results. When a human is searching for patterns we’ll normally only search for patterns we believe are there.
Unsupervised AI could show us things we never thought of asking. It could uncover those elusive “Unknown Unknowns”.
This is why I’m so excited for Unsupervised Learning in real estate. There are too many variables for humans to realistically model all outcomes at the moment. The more data we gather, the better computers will get at finding things out for us!
A Big Caveat
There are many major ethical questions to overcome in AI. One big caveat in Unsupervised Learning is the assumption that the computer will make “unbiased” assessments of data. While, in theory this is true, it is not true when the data itself is biased.
For example, most data about humans is skewed by the structural inequalities in society. One example was when a CV-screening AI learned to prefer men’s qualifications over women (Roose 2022). This is not surprising if the machine is associating pay levels with more male-dominated qualifications given the gender-pay gap in our society. In this case we need a human to intervene, to teach the computers more varied measures of effective CVs rather than just pay.
